Programming KNL--Architecture
Knights Landing
Intel Xeon Phi processors are based on so-called many integrated cores (MIC) architecture, aiming to provide high-performance computational abilities and portable programming interfaces, of which I consider tthe second feature the most attractive characteristic for programmers. The first generation (KNC) was announced at 2012, but actually there is a prototype--Knights Ferry proposed before. In this article, we would like to discuss both architectural and programming features about the most recent Xeon Phi Processor--Knights Landing.
Eye-catching Things
Standalone Processor
KNL could be used as a standalone processor or a coprocessor, and it could run several common operating systems, like REHL, CentOS, Fedora, and SUSE. While KNC does not support the function.
16GB HBM
The on package memory is similar to that of GPU, but somehow larger. Further, because intel supports different kinds of memory usage, which we would discuss in later section, it is also much more fexible.
Binary-compatible with Xeon
Without a long period of compiling and linking, applications could be directly run on Xeon Phi as long as they could run on Xeon.
Fabric on Package
Intel adopts its Omni-Path connection on KNL and claims that it could reach 100Gb/s speed in a cluster. Whereas I do not know whether it could beat Infiniband.
Look inside Cores

A KNL processor has 64-72 cores, connected by 2-d mesh structure, which means it takes no more than two routing steps to reach another core for a message. Each tile holds two cores and a 1MB L2 coherent cache.
The next graph shows details inside each core:

There are two scalar alus, two 512-bit alus, and out-of-order controllers on each core. Further, we have to notice that each core supports 4 hyper-threads. On the graph, red hexagons represent the points to select different thread.
Memory Modes
I think this is the most interesting feature that differs Xeon Phi with other accelerators like GPU. The on-package memory could be used very flexibly.
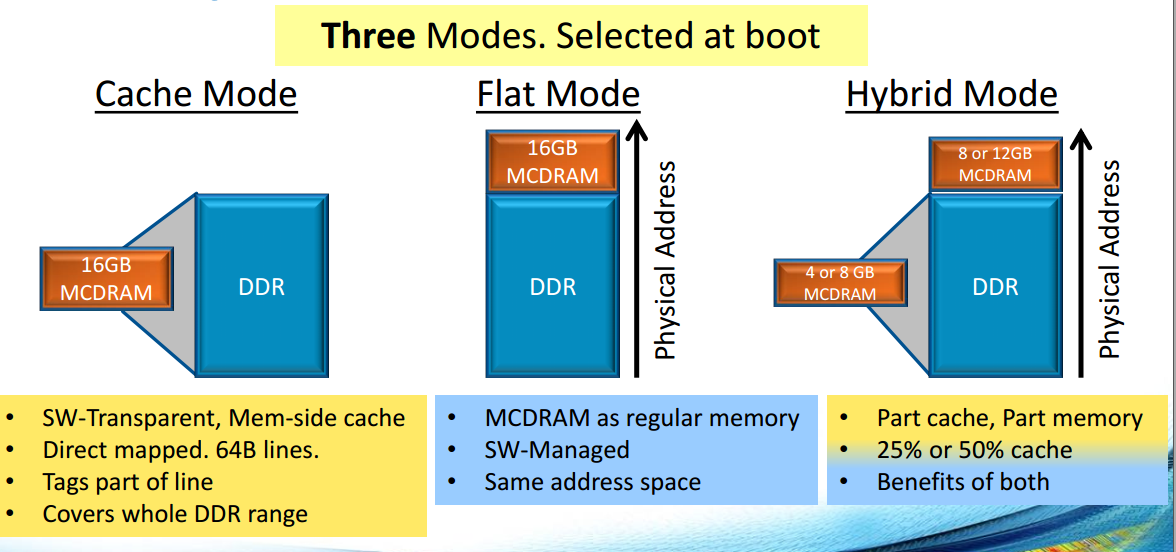
Cache Mode: the HBM is used as the last level cache.
Flat Mode: the HBM is used as another NUMA node, so we could adopt numactl to select a NUMA node.
Hybrid Mode: the HBM is partitioned into two parts, where a part is cache and another part is NUMA node. In this mode, we should adopt memkind to allocate memory explicitly, deciding where to allocate.
Clustering Modes
The last section is about how the cache coherent L2-cache communicate with each other. We would show three examples to illustrate their differences.
All-to-All

Each tag directory uniformly holds the memory address. Hence, if a data is request, it first sends a message to the remote directory, quiring whether the data is missing or not. The procedure might go through a long path.
Quadrant

The directory is splited into four qual pieces first. Therefore, requests take less steps to reach a tag directory. It is the default mode.
Sub-NUMA

Not only the tag directory mapping has its affinity, but also each core has its affinity memory accesses. Therefore, this mode is similar to the Xeon NUMA archtecture, which requires some external programming efforts.
We would discuss how to use 512-bit vector instructions, how to optimize cache usage in the next article.
Reference
[1] http://colfaxresearch.com/how-knl/
[2] Sodani, Avinash. "Knights landing (KNL): 2nd Generation Intel® Xeon Phi processor." Hot Chips 27 Symposium (HCS), 2015 IEEE. IEEE, 2015.
评论
发表评论